微服务
rpc微服务框架
- go micro
- Go Kit
- Gizmo
https://learnku.com/go/t/36973
go
包
runtime包里面的方法
runtime调度器是非常有用的东西,关于runtime包几个方法:
Gosched:让当前线程让出cpu以让其他线程运行,它不会挂起当前线程,因此当前线程未来会继续执行
NumCPU:返回当前系统的CPU核数量
GOMAXPROCS:设置最大的可同时使用的CPU核数
Goexit:退出当前goroutine(但是defer语句会照常执行)
NumGoroutine:返回真该执行和排队的任务总数
GOOS:目标操作系统
GOROOT:返回本机的GO路径
https://www.cnblogs.com/binHome/p/11928542.html
test
go的profile工具?
- pprof
GC
go语言的时候垃圾回收,写代码的时候如何减少小对象分配
go的gc原理了解吗?
GMP
gmp具体的调度策略
框架
gin框架的路由是怎么处理的?
MQ
mq底层数仓
redis
redis过期策略和内存淘汰策略
redis的存储结构?
redis的setnx底层怎么实现的?
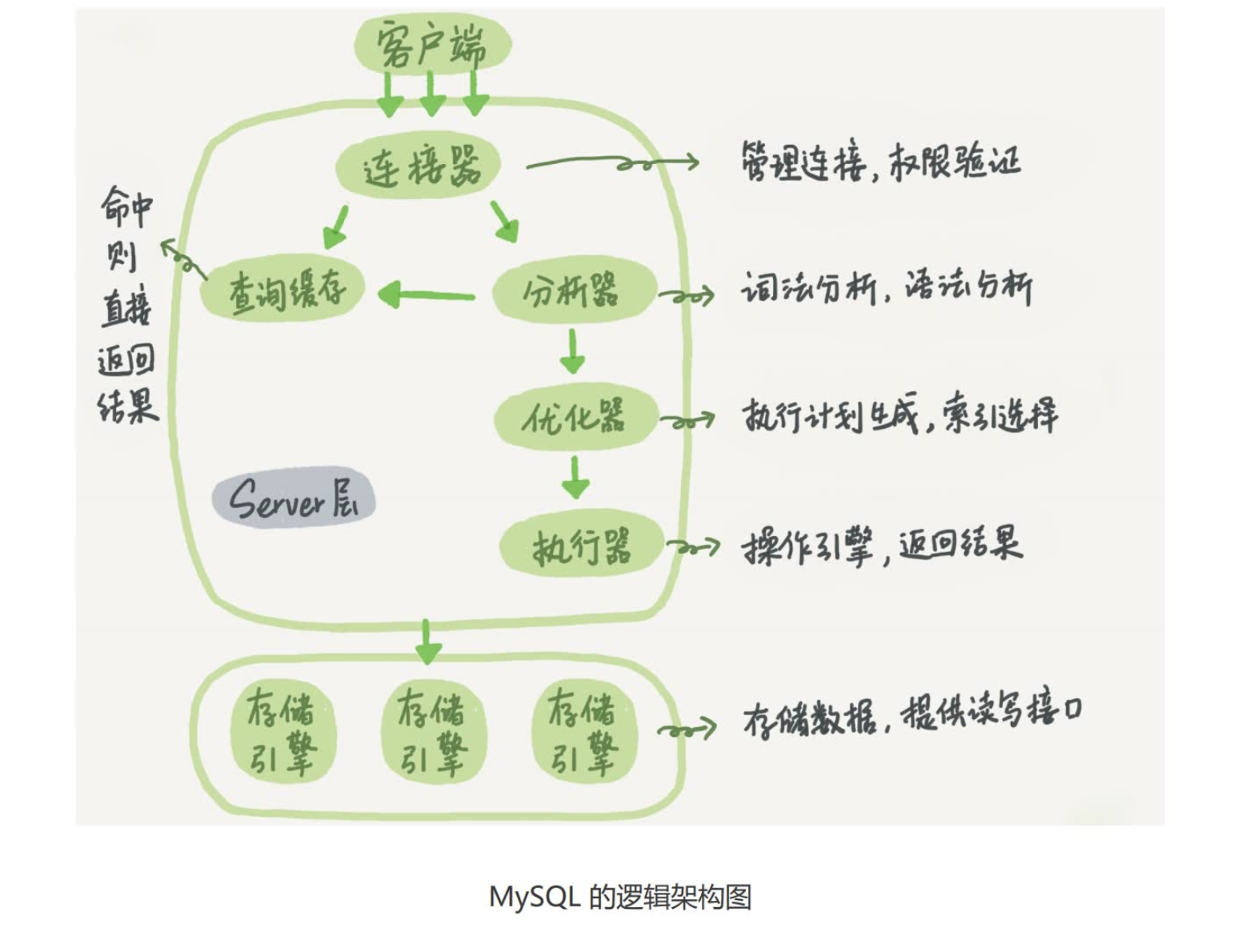
MySQL
一个update语句的执行过程
redo log WAL(write-Ahead logging)先写日志,再写磁盘
更新语句,innodb引擎会先把记录到redo log,并更新内存,此时更新完成。同时,innodb引擎会在合适的时候(空闲)更新到磁盘.类比掌柜记帐粉笔
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。

write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。write pos 和checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会失,这个能力称为crash-safe。
要理解 crash-safe 这个概念,可以想想我们前面赊账记录的例子。只要赊账记录记在了粉板上或写在了账本上,之后即使掌柜忘记了,比如突然停业几天,恢复生意后依然可以通过账本和粉板上的数据明确赊账账目。
bin log
sql索引优化问题
mysql索引结构
B+树和B树有什么区别
sql查询性能瓶颈处理方式
sql索引优化方式,explain字段含义
数据结构
实现map的方法除了哈希还有哪些?
网络
http和tcp有什么区别
用netstat看tcp连接的时候有关注过time_wait和close_wait吗?
fork的底层实现方式
限流熔断
限流算法
- 时间点计数法
- 时间范围计数
- 漏桶
- 令牌痛