Pipeline 模式
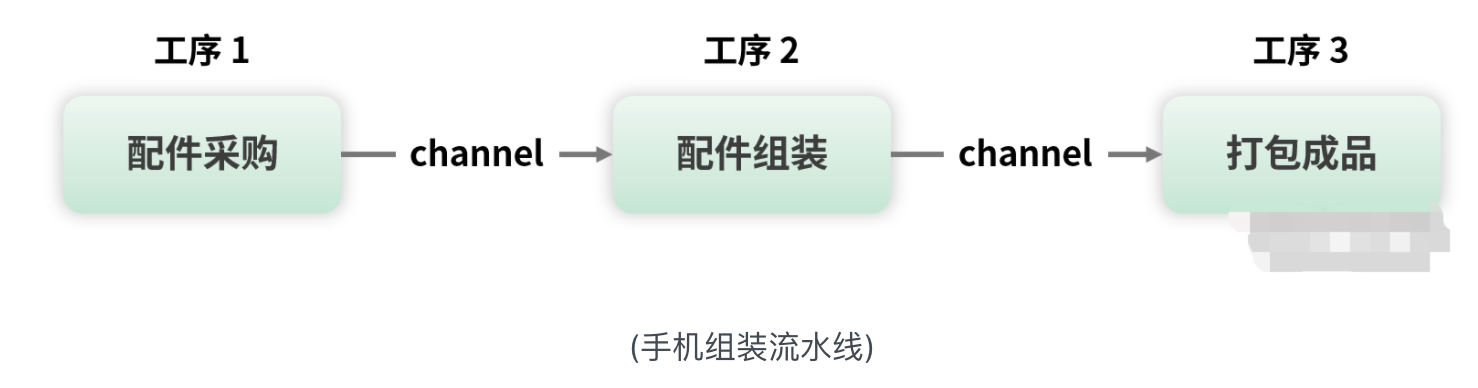
Pipeline 模式也称为流水线模式,模拟的就是现实世界中的流水线生产。以手机组装为例,整条生产流水线可能有成百上千道工序,每道工序只负责自己的事情,最终经过一道道工序组装,就完成了一部手机的生产。
从技术上看,每一道工序的输出,就是下一道工序的输入,在工序之间传递的东西就是数据,这种模式称为流水线模式,而传递的数据称为数据流。
流程:
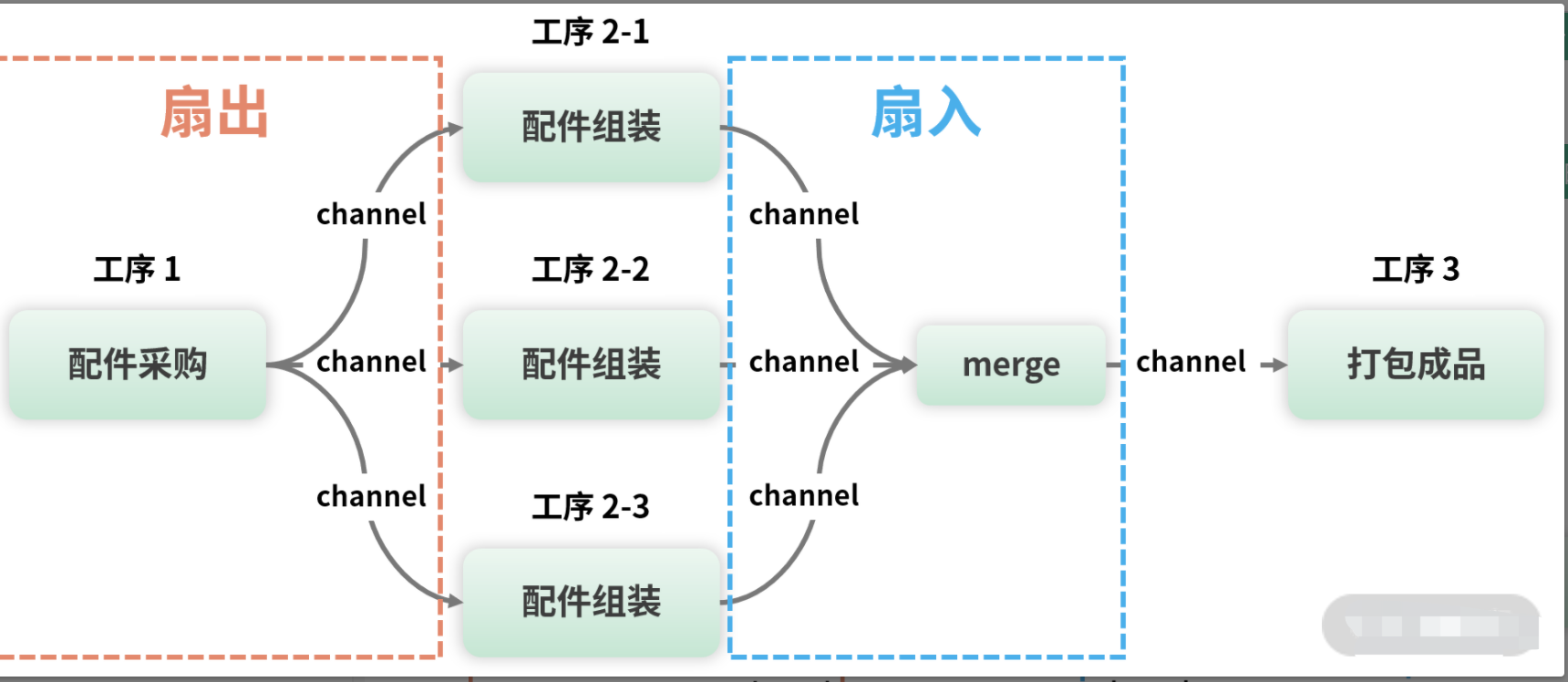
扇出和扇入模式
fallin-fallout
手机流水线经过一段时间的运转,组织者发现产能提不上去,经过调研分析,发现瓶颈在工序 2 配件组装。工序 2 过慢,导致上游工序 1 配件采购速度不得不降下来,下游工序 3 没太多事情做,不得不闲下来,这就是整条流水线产能低下的原因。
为了提升手机产能,组织者决定对工序 2 增加两班人手。人手增加后,整条流水线的示意图如下所示:
Futures 模式
Pipeline 流水线模式中的工序是相互依赖的,上一道工序做完,下一道工序才能开始。但是在我们的实际需求中,也有大量的任务之间相互独立、没有依赖,所以为了提高性能,这些独立的任务就可以并发执行。
举个例子,比如我打算自己做顿火锅吃,那么就需要洗菜、烧水。洗菜、烧水这两个步骤相互之间没有依赖关系,是独立的,那么就可以同时做,但是最后做火锅这个步骤就需要洗好菜、烧好水之后才能进行。这个做火锅的场景就适用 Futures 模式。
Futures 模式可以理解为未来模式,主协程不用等待子协程返回的结果,可以先去做其他事情,等未来需要子协程结果的时候再来取,如果子协程还没有返回结果,就一直等待。
//洗菜
func washVegetables() <-chan string {
vegetables := make(chan string)
go func() {
time.Sleep(5 * time.Second)
vegetables <- "洗好的菜"
}()
return vegetables
}
//烧水
func boilWater() <-chan string {
water := make(chan string)
go func() {
time.Sleep(5 * time.Second)
water <- "烧开的水"
}()
return water
}
func main() {
vegetablesCh := washVegetables() //洗菜
waterCh := boilWater() //烧水
fmt.Println("已经安排洗菜和烧水了,我先眯一会")
time.Sleep(2 * time.Second)
fmt.Println("要做火锅了,看看菜和水好了吗")
vegetables := <-vegetablesCh
water := <-waterCh
fmt.Println("准备好了,可以做火锅了:",vegetables,water)
}
Futures 模式下的协程和普通协程最大的区别是可以返回结果,而这个结果会在未来的某个时间点使用。所以在未来获取这个结果的操作必须是一个阻塞的操作,要一直等到获取结果为止。
如果你的大任务可以拆解为一个个独立并发执行的小任务,并且可以通过这些小任务的结果得出最终大任务的结果,就可以使用 Futures 模式。
参考:https://www.cnblogs.com/-wenli/p/12349831.html