map
总体来说golang的map是hashmap,是使用数组+链表的形式实现的,使用拉链法消除hash冲突。
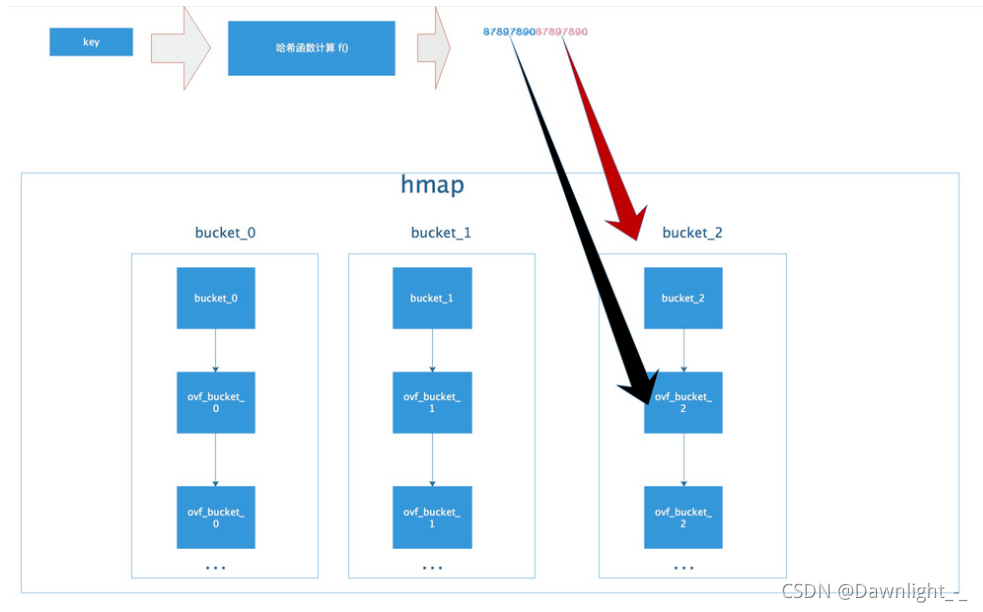
map使用散列表(hash)实现。在这个散列表中,主要出现的结构体有两个,一个叫 hmap(a header for a go map),一个叫 bmap(a bucket for a Go map,通常叫其 bucket)。
实现原理: https://www.cnblogs.com/dawnlight/p/15552513.html https://segmentfault.com/a/1190000039101378
map扩容:
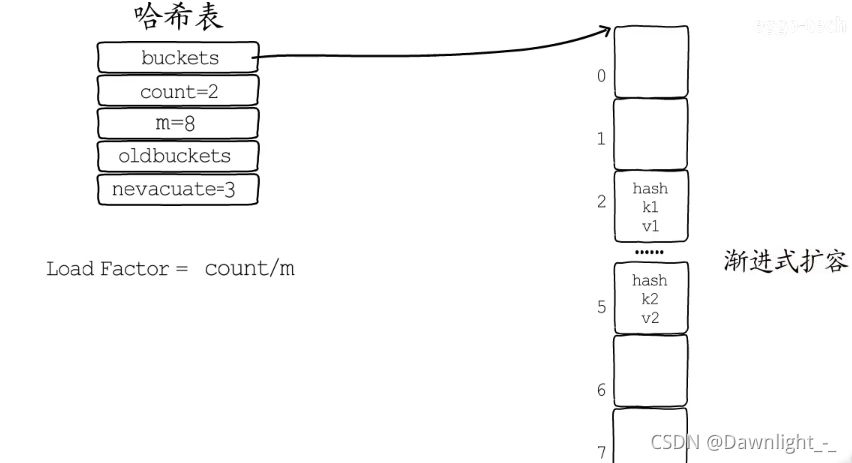
判断扩充的条件,就是哈希表中的负载因子(即loadFactor)。 每个哈希表的都会有一个负载因子,数值超过负载因子就会为哈希表扩容。 Golang的map的加载因子的公式是:
map长度 / 2^B(这是代表bmap数组的长度,B是取的低位的位数)阈值是6.5。其中B可以理解为已扩容的次数。
触发条件:
- 装填因子是否大于 6.5
- overflow bucket 是否太多
渐进式扩容 需要扩容时就要分配更多的桶(Bucket),它们就是新桶。需要把旧桶里储存的键值对都迁移到新桶里。如果哈希表存储的键值对较多,一次性迁移所有桶所花费的时间就比较显著。 所以通常会在哈希表扩容时,先分配足够多的新桶,然后用一个字段(oldbuckets)记录旧桶的位置。 再增加一个字段(nevacuate),记录旧桶迁移的进度。例如记录下一个要迁移的旧桶编号。 在哈希表每次进行读写操作时,如果检测到当前处于扩容阶段,就完成一部分键值对迁移任务,直到所有的旧桶迁移完成,旧桶不再使用,才算真正完成一次哈希表的扩容。 像这样把键值对迁移的时间分摊到多次哈希表操作中的方式,就是渐进式扩容,可以避免一次性扩容带来的性能瞬时抖动。
扩容规则:
- 双倍扩容:扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一 次性搬迁完毕,每次最多只会搬迁 2 个 bucket
- 等量扩容:重新排列,极端情况下,重新排列也解决不了,map 成了链表, 性能大大降低,此时哈希种子 hash0 的设置,可以降低此类极端场景的发 生
map查找
map 采用的是哈希查找表,由一个 key 通过哈希函数得到哈希值,64 位系统中就生成一个 64bit 的哈希值,由这个哈希值将 key 对应到不同的桶 (bucket)中,当有多个哈希映射到相同的的桶中时,使用链表解决哈希冲 突。
key 经过 hash 后共 64 位,根据 hmap 中 B 的值,计算它到底要落在哪个桶 时,桶的数量为 2^B,如 B=5,那么用 64 位最后 5 位表示第几号桶,在用 hash 值的高 8 位确定在 bucket 中的存储位置,当前 bmap 中的 bucket 未找到,则查 询对应的 overflow bucket,对应位置有数据则对比完整的哈希值,确定是否 是要查找的数据。 如果两个不同的 key 落在的同一个桶上,hash 冲突使用链表法接近,遍历 bucket 中的 key 如果当前处于 map 进行了扩容,处于数据搬移状态,则优先从 oldbuckets 查找
添加关联到map并访问关联和数据
map[Key_Type]Value_Type
scene := make(map[string]int)
scene["route"] = 66
fmt.Println(scene["route"])
v :=scene["route2"] //尝试查找一个不存在的键,返回的将是value_type的默认值
fmt.Println(v)
/**
66
0
*/
填充内容方式
m := map[string]string{
"W": "forward",
"A": "left",
"D": "right"
}
并没有使用make,而是使用大括号进行内容定义,就像json格式一样,健值对,并使用逗号分割。
取值
m = map[string]int{}
i := m["route"]
如果route存在,就返回那个值,如果不存在,返回0值,也就是说,根据这个value的类型,返回缺省值,比如string,就返回“”,int 就返回0
判断map中key是否存在
if _, ok := map[key]; ok {
//存在
}
m := make(map[string]string)
m["b"] = "1"
val,exist := m["a"]
val1,exist1 := m["b"]
fmt.Println(val,exist)
fmt.Println(val1,exist1)
// false
// 1 true
delete()从map中删除健值对
delete(map, 键)
//map 要删除的实例
清空map中的所有元素
清空map的唯一办法就是重新make一个新的map。 不用担心垃圾回收的效率,Go中的并行垃圾回收效率比写一个清空函数高效的多。
能够在并发环境中使用的map——sync.Map
Go中的map在并发环境下,只读是线程安全的,同时读写线程不安全。
package main
func main() {
m := make(map[int]int)
// 并发情况下读写 map 时
go func(){
// 不停地对map进行写入
for {
m[1] = 1
}
}()
go func(){
// 不停地对map进行读取
for {
_ = m[1]
}
}()
// 无限循环, 让并发程序在后台执行
for {
_:
}
}
出现错误: fatal error: concurrent map read and map write
使用sync.map (对key加锁)
package main
import (
"fmt"
"sync"
)
func main() {
m := sync.Map{}
// 并发情况下读写 map 时
go func(){
// 不停地对map进行写入
for {
m.Store(1,1)
}
}()
go func(){
// 不停地对map进行读取
for {
_,err := m.Load(1)
fmt.Println(err)
}
}()
// 无限循环, 让并发程序在后台执行
for {
_:
}
}
提供LoadOrStore方法,key存在返回已存在的值,设置值不生效;如果已经stored,loaded result标记false,反之true。LoadOrStore returns the existing value for the key if present. Otherwise, it stores and returns the given value. The loaded result is true if the value was loaded, false if stored.
参考官网:https://golang.org/pkg/sync
-a=31264289