对mysql Innodb存储引擎下b+树索引及算法进行简单剖析,做下记录。
B+树
B+树从平衡二叉树演化而来,但B+树不是一个二叉树,严格来说是多路平衡多叉树。
B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到查找的数据。
二叉查找树 左子树的键值总是小于根的键值,右子树的键值总是大于根的键值。
通过中序遍历可以得到键值的排序输出。
对于一个非满的二叉查找树,左子树的高度可能远小于右子树的高度或者二叉树退还成链表,查询的效率就会收到影响,所以出现了平衡二叉树(或称为AVL)。
平衡二叉树:
- 符合二叉查找树的定义
- 满足任何节点的左右子树的高度最大差为1。
B+树
B+树是为磁盘或其他直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶节点中,各节点指针进行连接。
B+树的插入操作
B+树的插入必须保证插入后的叶节点中的记录依然排序,同时考虑插入B+树的三种情况。
| Leaf Page Full | Index Page Full | 操作 |
|---|---|---|
| No | NO | 直接将记录插入叶节点 |
| Yes | NO | 1. 拆分Leaf page; 2. 将中间的节点放入到Index Page中; 3. 小于中间节点的记录放左边; 4. 大于等于中间节点的记录放右边; |
| Yes | Yes | 1. 拆分Leaf Page; 2. 小于中间节点的记录放左边; 3. 大于等于中间节点的记录放右边; 4. 拆分Index Page; 5. 小于中间节点的记录放左边; 6. 大于中间节点的记录放右边; 7. 中间节点放入上一层Index Page。 |
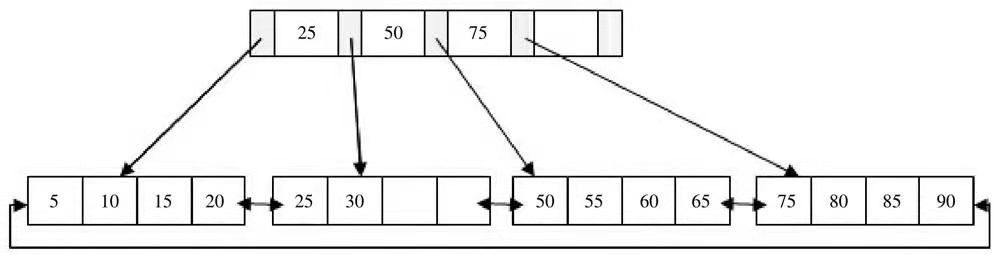
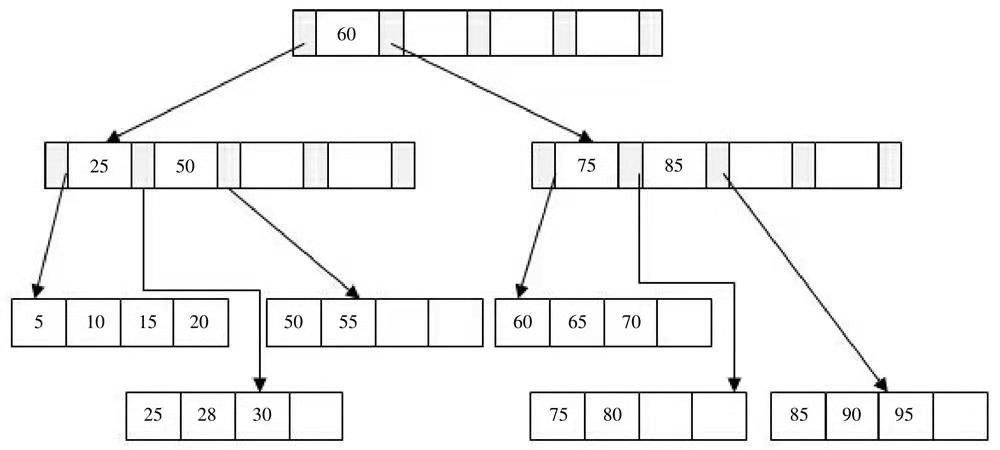
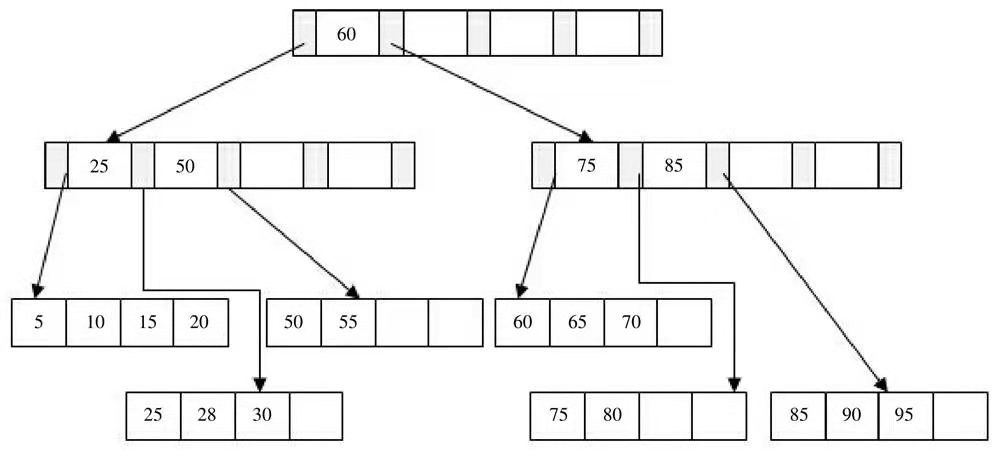
实例分析下B+树
- 插入28键值,此时发现Leaf page 和Index page都没有满,直接插入即可
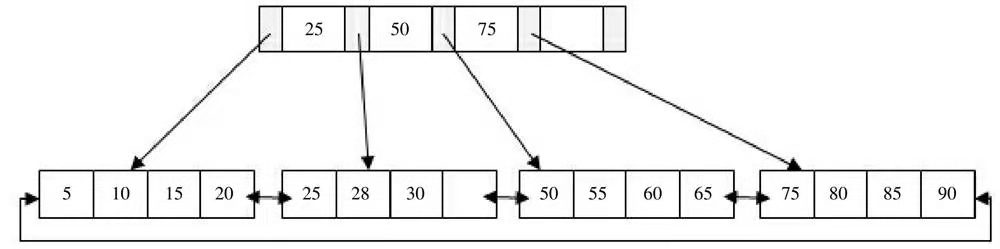
- 插入70键值,发现Leaf page已经满了,Index page没有满,此时插入到Leaf page中,值为50、55、60、65、70,根据中间值60拆分叶节点
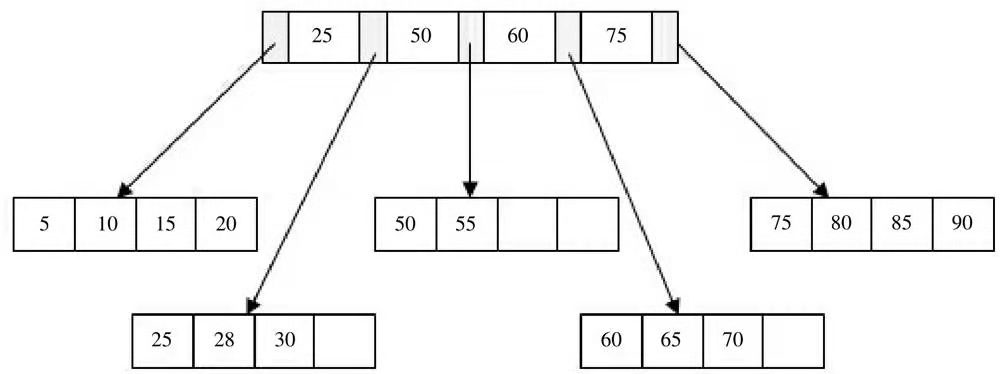
- 最后插入95,此时Leaf page和Index page都满了,这时需要做二次拆分。
不管怎么变化,B+树总是会保持平衡。但为了保持平衡需要做大量的拆分页操作,而B+树主要用于磁盘,因此页的拆分意味着磁盘的操作,在可能的情况下尽量减少页的拆分。故B+树提供了旋转(rotation)功能。
页的旋转 避免了页的拆分
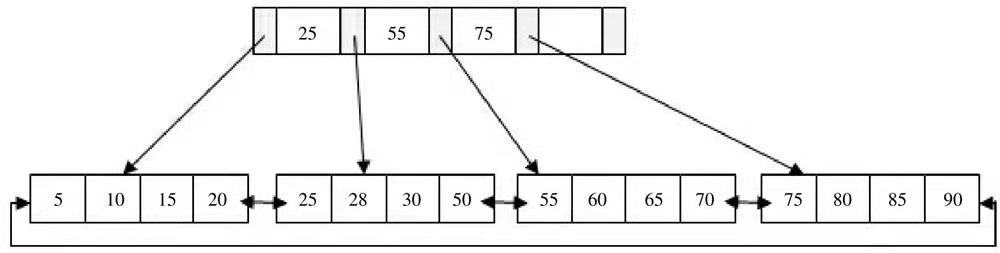
旋转发生在Leaf Page已经满了、但是左右兄弟节点没有满的情况下。这时B+树并不会急于去做拆分的操作,而是将记录移到所在页的兄弟节点上。
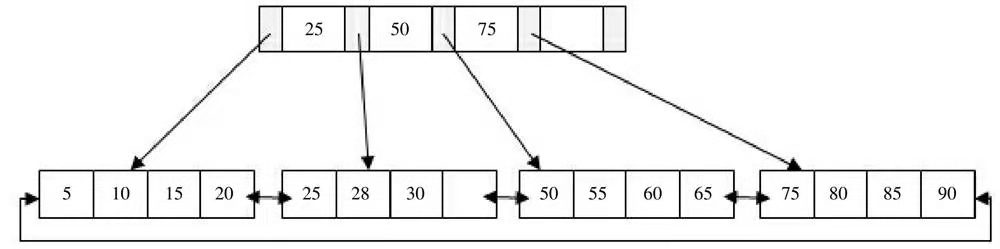
B+树删除操作
B+树使用填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。
删除操作必须保证删除后的叶节点中的记录依然有序,与插入不同的是,删除根据填充因子的变化来衡量。

//todo 删除操作三种情况
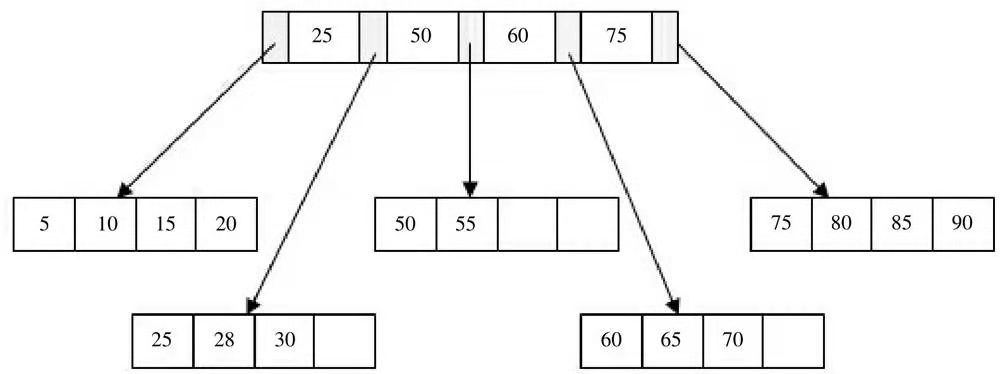
B+树索引
B+树索引本质是B+树在数据库中的实现。在数据库中,B+树的高度一般都在2~3层,即在查询某一键值的行记录,最多只需要2~3次IO。 一般的磁盘每秒至少可以做100次IO,2~3次意味着查询时间只需0.02~0.03秒。
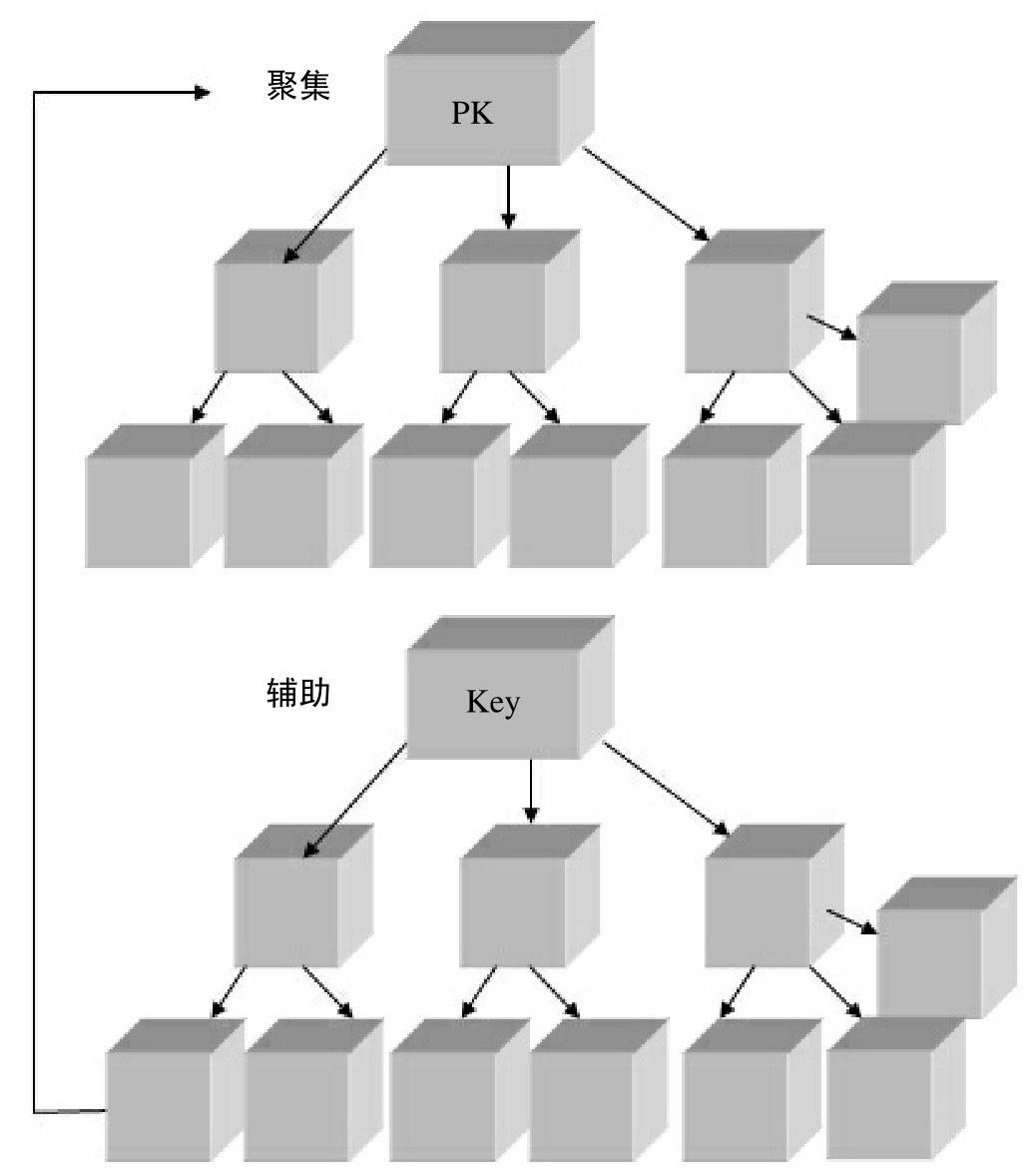
B+树索引分为聚集索引和辅助聚集索引,内部都是B+树,高度平衡,叶节点存放着所有的数据。
聚集索引
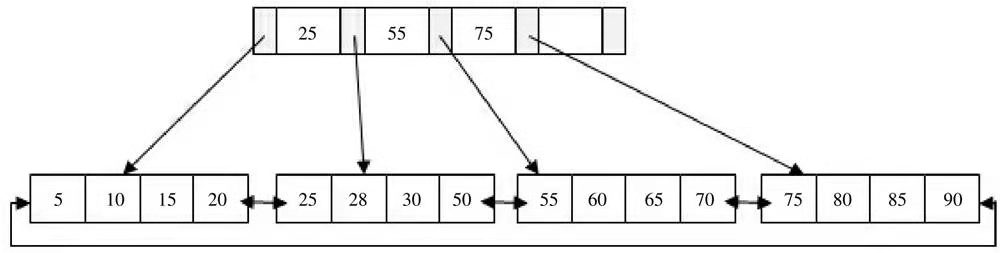
InnoDB存储引擎是索引组织表,即表中数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一棵B+树,同时椰子节点中存放的是整张表的行记录数据, 也将聚集索引的叶子结点称为数据页。
聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。同B+树结构一样,每个数据页都通过一个双向链表来进行连接。
由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。
多数情况下 ,查询优化器倾向于采用聚集索引。(因为聚集索引能够在B+树索引的叶子结点直接找到数据,此外由于定义了数据的逻辑顺序,聚集索引能够特别快的访问针对范围的查询)
聚集索引的存储并不是物理上的连续,而是逻辑上连续。有两点:
- 页是通过双向链表连接,页按照主键顺序排列;
- 每个页的记录通过双向链表进行维护,物理存储同样不按照主键存储。
优点:对于主键的排序查找和范围查找(双向链表)速度非常快。
辅助索引(非聚集索引)
叶子节点并不包含行记录的全部数据。叶子结点出了包含逐渐键值以外还包含了一个书签(该书签用来告诉InnoDB存储引擎哪里找到与索引相对应的行数据,书签就是对应行数据的聚集索引键)。
图示 聚集索引和辅助索引的关系: